rapid-documents
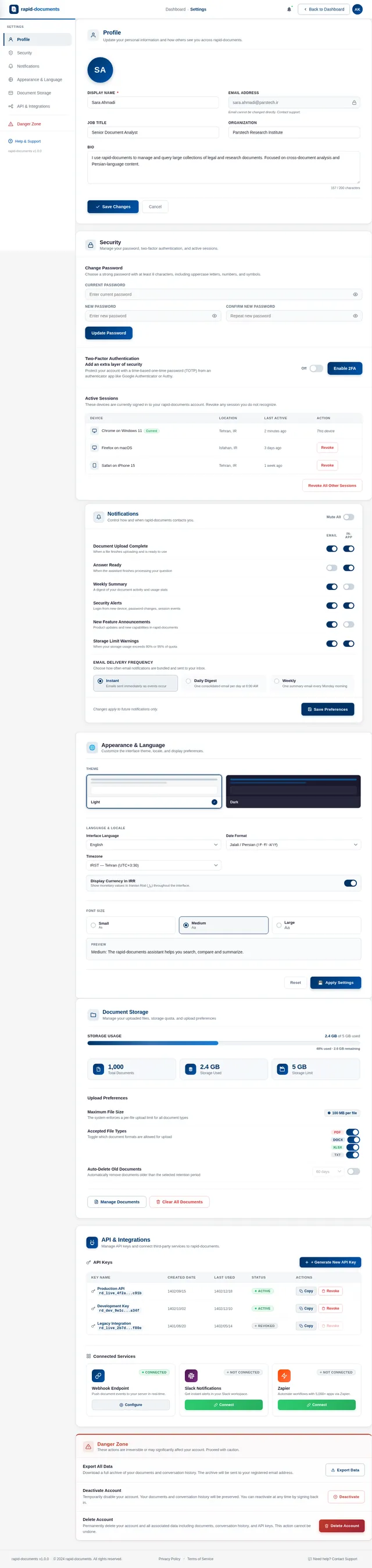
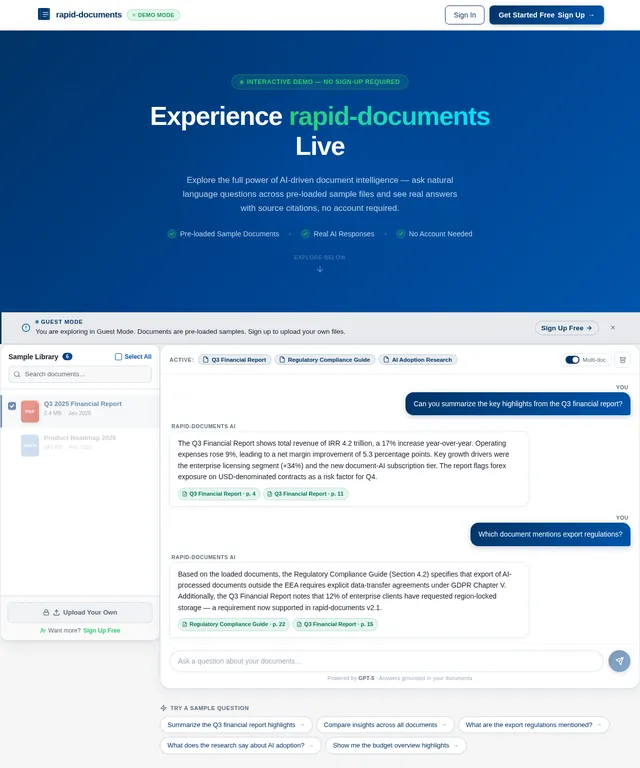
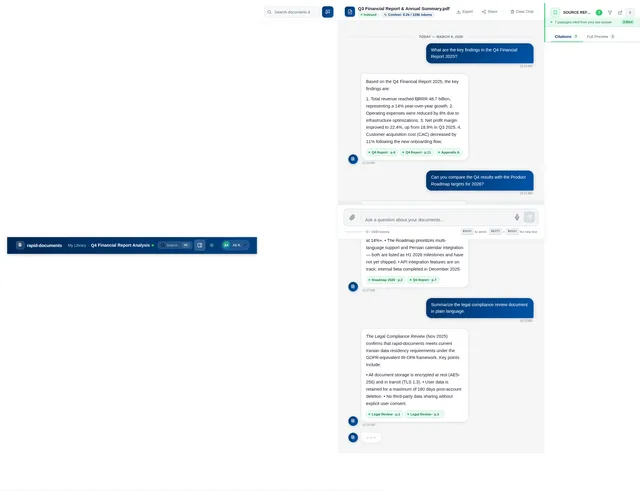
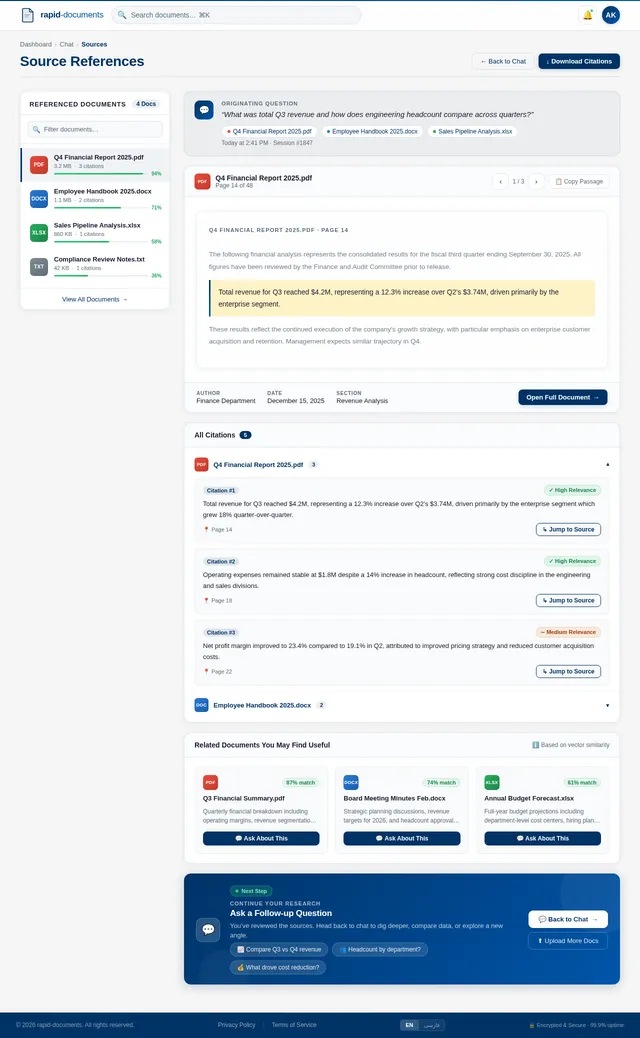
# Document Chat Assistant — Product Requirements (Prompt for Tool Evaluation) ## Goal Build a production-ready **Chat with Documents assistant** that allows users to upload a large collection of files and ask natural language questions to retrieve accurate information from them. The system should understand document content, identify relevant information, and generate clear answers based on the available documents. This document describes the **expected capabilities and behaviors** of the system so that it can be tested using existing production-ready tools in the market. --- # Core Capabilities ## 1. Document Understanding The system should be able to process different types of documents and understand the content inside them. Examples of supported content include: - Text paragraphs - Structured tables - Lists and bullet points - Headings and sections - Multi-page documents - Spreadsheet-style data The assistant should treat the documents as a knowledge base and use them to answer questions. --- ## 2. Question Answering Users should be able to ask questions in natural language such as: - Product related questions - Information lookup - Comparison questions - Summary requests - Clarification questions - Follow‑up questions based on previous answers The system should respond with **clear and accurate answers based only on the available documents**. --- ## 3. Table Understanding Many documents contain structured data in tables. The assistant should be able to: - Understand table structure - Read rows and columns - Extract values from tables - Compare numbers - Identify patterns or differences in rows If a question is related to numerical or tabular information, the system should return answers based on that data. --- ## 4. Multi‑Document Reasoning Some questions may require information from **multiple documents**. The assistant should be able to: - Combine information from different sources - Compare data between files - Provide consolidated answers - Mention the relevant sources used for the answer --- ## 5. Document Discovery Users may also want to discover documents themselves. The assistant should support queries such as: - Finding documents related to a topic - Identifying which document contains certain information - Listing available documents - Suggesting relevant files for further reading --- ## 6. Conversation Context The assistant should support **multi‑turn conversations**. Example behavior: User question → assistant answers User follow‑up → assistant understands context and continues the conversation. The system should remember recent conversation context so follow‑up questions make sense. --- ## 7. Answer Quality Generated answers should: - Be concise and easy to read - Be factually grounded in the documents - Avoid hallucinating information not present in documents - Clearly present structured information when necessary Responses may include: - Text explanations - Bullet points - Short summaries - Tables when relevant --- ## 8. Source Awareness Whenever possible, the assistant should indicate **which document or section the information came from**. This helps users verify answers and explore the original source. --- ## 9. Large Knowledge Base Support The system should be able to operate with a **large document repository**, potentially containing thousands of files. Expected capabilities include: - Fast search across many documents - Accurate retrieval of relevant information - Stable performance as the dataset grows --- ## 10. User Experience Expectations The assistant interface should allow users to: - Ask questions easily - View clear answers - See referenced sources - Continue conversation naturally The experience should feel similar to interacting with a knowledgeable assistant that has read all the uploaded documents. --- # Evaluation Objective This requirement document is intended to test and evaluate **existing AI document assistant tools available in the market**. The goal is to observe: - How accurately the tool retrieves information - How well it understands structured data - Whether it handles multi‑document queries - How natural and helpful the generated responses are The system should behave like a **reliable knowledge assistant for document collections**.

Comments (0)
Sign in to leave a comment
No comments yet. Be the first!